移动端 GPU 架构知识总结
由于工作原因,博主针对移动端的 GPU 架构进行了学习,并在这里总结了一些移动端 GPU 架构的知识点。
希望通过这篇文章能让自己对移动端 GPU 架构有一个更加全面的了解,并能帮助到更多的人。对于其中的部分知识点,目前博主缺少测试进行验证,欢迎各路大神指出错误。
前沿知识
在正式介绍 TBDR 架构会涉及大量的专用名词,需要先了解一些前沿知识,这里指路这篇文章:
移动平台GPU硬件学习与理解 - 蕾芙丽Reverie的文章 - 知乎
移动端 GPU 为什么采用 TBR 架构?
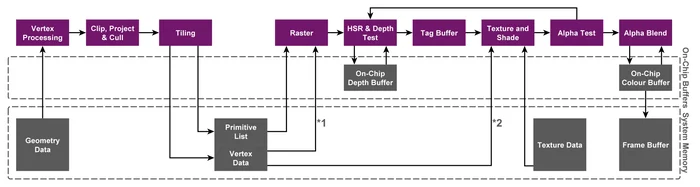
现代移动端 GPU 往往采用 TBDR(Tile-Base-Deffered-Rendering) 架构,与之相对的 PC 端往往采用 IMR(Immediate-Rendering) 架构,它们的硬件设计区别很大。出现这种区别的主要原因是移动端设备要考虑功耗问题,功耗意味着发热,如果无法解决发热就会导致核心降频。主机有很多种办法来解决散热问题,而移动端设备只能想办法降低功耗。在 GPU 渲染中,对功耗影响最大的是带宽,而 TBR 架构的发明正是为了解决高带宽的问题。
目前移动端 GPU 的主流厂商有 Mali、Adreno、PowerVR,它们三个占据了目前绝大部分的市场,并且都采用了基于 TBR 的架构。
那么 TBR 架构是很么呢?
回答这个问题之前,我么可以先看一下 IMR 的渲染流程:
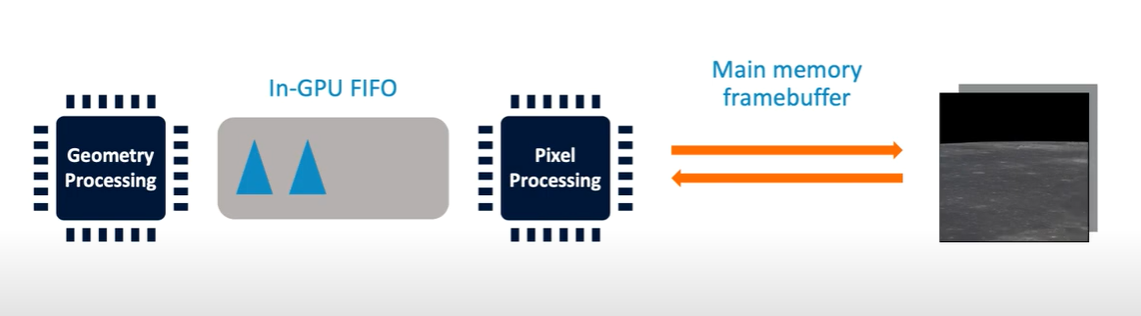
渲染流程分为几何处理阶段和像素处理阶段,这两个阶段中间依靠一个 FIFO 缓冲相连,几何处理完成后的多边形会被推入到这个缓冲中,并在缓冲用完时暂停,而像素处理阶段则从这个缓冲中取出这些多边形进行渲染。这种架构下,像素渲染阶段取到的多边形最后可能会落在屏幕上的任意一个地方,这个范围是比较大的,只能存储在显存(DRAM)中。
频繁访问距离 GPU 较远的显存会带来很大的功耗,那么我们能够很自然的能够想到,如果能够把原先对显存的频繁访问换成对 On-chip Memory(L1、L2 Cache,一种 SRAM)的频繁访问,完成所有操作后一次性将画面回拷到 DRAM 就好了。不过由于 SRAM 是比较小的,所以为了这样做,移动端还需要将一个巨大的 Framebuffer 分成许多小块,使其可以被这些 On-chip Memory 容纳,块的多少取决于硬件的 SRM 的大小。这样 GPU 就可以通过访问一块块的 SRAM 的方式访问 Framebuffer,一整块都访问完后再整体转回显存上,带宽消耗过高的问题就解决了,这种方案也就自然被我们叫做 Tile-Based Rendering。
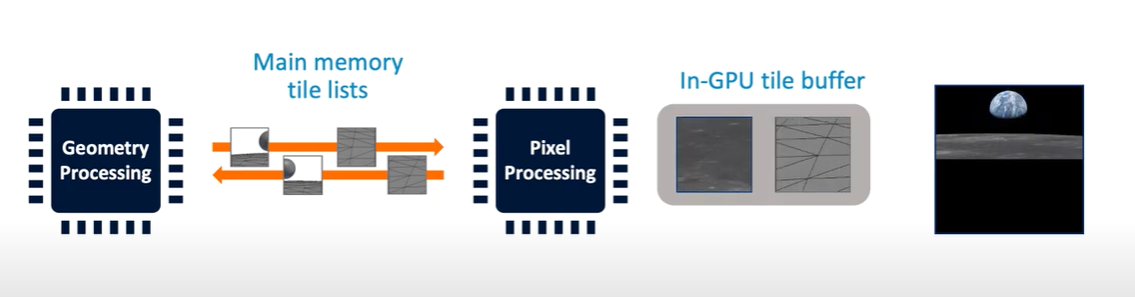
TBR 流程
不同厂商在设计 TBR 时很多概念的叫法都不太一样,不过基本的流程都像下面这样(以 Mali 来举例):
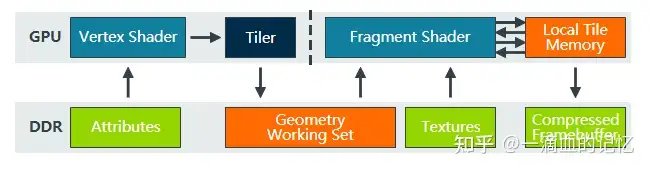
和 IMR 对比一下:
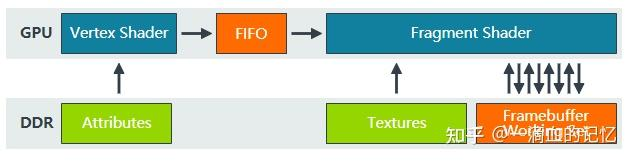
TBR 架构相当于将 IMR 的渲染流程分成两个阶段来进行,Binning(Tiling) Pass 和 Rendering Pass,Binning Pass 完成后会将图元放到不同的的 Tile List 中,这里的 Tile List 可以理解为一个元素为图元链表的固定长度数组,数组的长度为 Tile 的数量。
用简单的伪代码和动图来表达这两个架构的渲染流程:
IMR
伪代码:
1 | |
动图(左侧 framebuffer,右侧 depth buffer):

TBR
伪代码:
1 | |
Pass one 动图:

Pass two 动图(左侧 framebuffer,右侧 depth buffer):
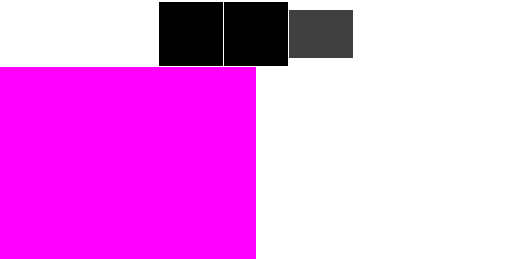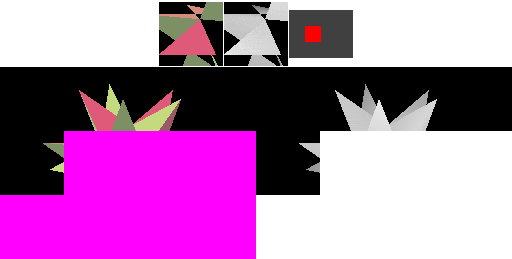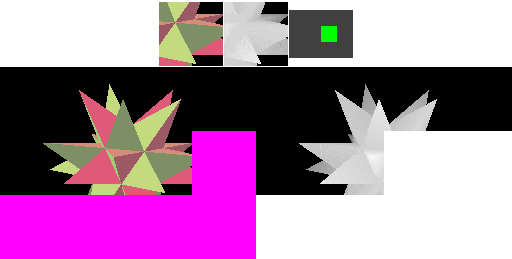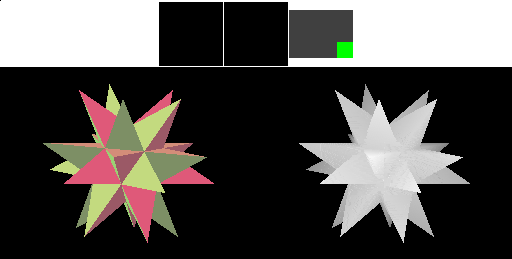
TBDR 流程
PowerVR 采用 HSR 技术(Hidden Surface Removeal)对 TBR 架构进一步进行了优化,所以我们称它的这种架构为 TBDR,D 即为 Defer。HSR 技术某种程度上相当于优化版的硬件 EarlyZ。
EarlyZ
首先介绍一下 EarlyZ,这个技术目前已广泛存在于 GPU 硬件中,通过在渲染不透明图元前先进行一次深度检测进行剔除,从而减少不必要的绘制。由于这种技术依赖于深度缓冲,想让其生效有两种方式:
第一种方式是 PreDepth Pass,单独使用一个 Pass 渲染所有不透明物体的深度,等正常渲染场景时关闭深度写入,EarlyZ 即可由 drive 生效剔除看不见的片段。这种方案多用在延迟渲染中,毕竟在前向渲染添加一个 Pass 意味着多了一倍的顶点、光栅化和深度测试。
第二种方式则是预先对不透明物体从近到远进行排序,远处的物体在 EarlyZ 阶段便会被剔除。这种方法对不透明物体进行排序的要求不仅增加了 CPU 的负担,还无法完全避免 Overdraw,因为有些相互重叠的图元是无法对他们的远近进行排序的:
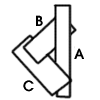
虽然有着这些局限性,但因为消耗的性能相对较少,所以一般都使用这种方案。
HSR
HSR 技术中包含了 EarlyZ 的部分,是能够 保证 0 Overdraw 的(建立在所以物体都是不透明物体的前提下)。它的原理很简单,当一个 fragment 通过 EarlyZ 时,不立即执行着色操作,而是记录该 fragment 目前对应的是哪个图元,之后渲染时遍历所有的像素,查找这个像素对应的图元并将其渲染出来。这相当于每个像素只执行了最后通过 EarlyZ 的 PixelShader。
不过,遇到 AlphaTest 等透明物体需要的特性时,EarlyZ 会失效并转为 LateZ,HSR 也会受到影响,其 Defer 流程会被中断导致渲染性能降低(不会特别夸张)。
HSR 技术的产生意味着在 PowerVR 架构的设备上我们可以不用进行这些排序了。(笔者写下这篇文章时,其他厂商也避开 HSR 技术专利发展出了类似的技术,譬如 Mali 的 FPK、Adreno 的 low resolution z)
TB(D)R 的问题
整体上来看,由于 TBR 需要一块块地绘制然后回拷,所以整体速度是比 IMR 要慢的,这也是主机 GPU 不使用 TBR 的原因。如果手机可以解决带宽产生的功耗问题,或者说 SRAM 可以做的足够大了,那就没有 TBR 的事了。我们可以简单认为 TBR 牺牲了执行效率,但是解决了带宽功耗的问题。
由于 TBR 的架构复杂化了 Geometry Processing 的流程,导致诸如 Tessellation 和 Geometry Shader 的几何处理技术表现很差。
关于移动端的优化建议,可以移步到这篇文章:针对移动端TBDR架构GPU特性的渲染优化 - feng的文章
参考文章
移动平台GPU硬件学习与理解 - 蕾芙丽Reverie的文章 - 知乎
移动设备GPU架构知识汇总 - Sparrowfc的文章 - 知乎
针对移动端TBDR架构GPU特性的渲染优化 - feng的文章